



From Canvas to Code - Part 2
Focusing on user needs and delivering value incrementally

Intro
If you’ve not read Discovery & Definition: Steps to Shape Successful Data Products - Part 1 then I highly suggest you read that first (I’ll wait here for you).
🎗️In Part 1, we explored how to go wide in the problem space. We had many meaningful conversations, interviews, and brainstorming sessions with our customers to get an agreed understanding of what the problem we want to solve.
What we plan to cover in From Canvas to Code is where things get fun and get to write some code whilst still keeping focus on the impact our data product will have. Just like in part 1, all examples are related to our fictional company 🍔 GrillTech Burgers.1
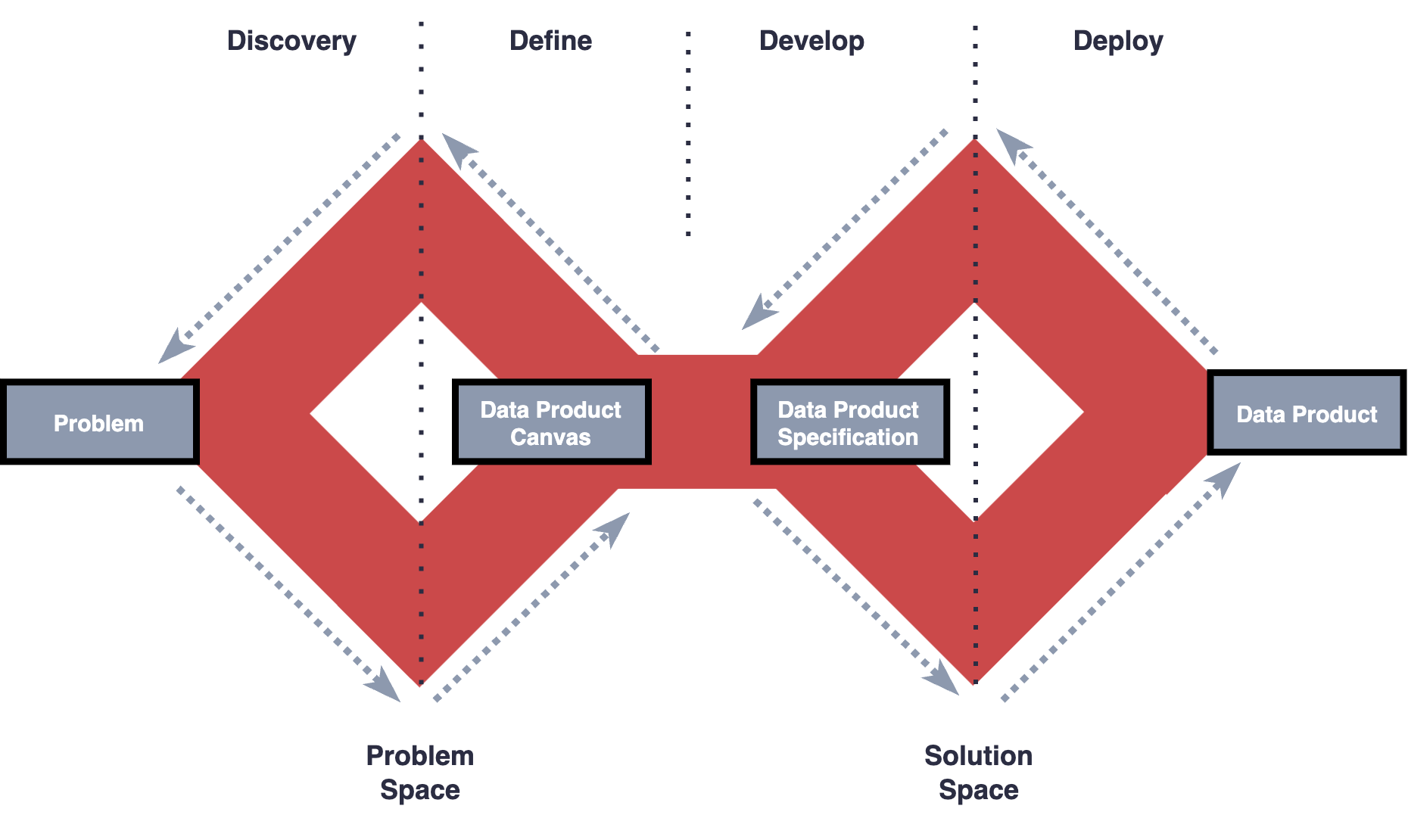
The Transition from Problem Space to Solution Space (Develop)
Like the entire data product lifecycle, the steps within this phase are iterative, and it’s expected that you iterate as much as needed to deliver the outcome your customer requires.
Conceptualisation & Ideation
There is both an art and a science in conceptualising & identifying the best solution for a problem. To ideate ideas on possible solutions, conduct as many workshops needed with your team and customers. In each workshop, consider what you learn and what feedback you get, and how this will impact the original assumptions and the final solution.
When ideating a solution, consider:
Slice Thin for Quick Wins: How can you thinly slice this data product to learn and deliver value fast?
Revisit Past Solutions: Has this problem been solved before, perhaps unsuccessfully, or solved in a silo? If you have a data catalogue, check it and consult other data teams.
Simplicity over Complexity: When ideating solutions, consider that you are still iterating fast, and it’s OK to keep the solution as simple as possible. Avoid complexity and do not fall into the trap of bikeshedding.
Laser Focus on Outcomes: Have a laser focus on the problem statement, expected benefits and outcome when considering a solution.
How do your customers feel?: This is important. This isn’t your data product, you're not using it every day, they are. How they feel is relevant, unless you like checking your Power BI activity report to see 0 views.
Ensure you prepare for your ideation workshops beforehand and let attendees know the outcome you’re hoping to achieve. Finally, speak their language.
Sometimes the best solution is no solution. If you can change a business process, remove waste or *close your eyes* just use excel and achieve the outcome. Then this is great outcome.
Once you've generated potential solutions, the next critical step is to validate the assumptions underlying these ideas to ensure their feasibility.
Validate your assumptions
As you start to progress from uncertainty to certainty, consider what was documented in your data product canvas and if these assumptions are true or false. You will start to get additional information, see actual data, identify data realities and learn more about how the business works. The takeaway here is to iterate your requirements as well as your data product as you learn more to ensure clarity in the team.
Product Thinking for Data Products
Ideation eventually narrows into a proposed solution and fingers will hit keyboards and your product mindset does not end because you can’t see post-it notes on canvases. '
Data products are not just technical solutions, but user-centric assets that should continuously provide value. Product thinking encourages building iteratively while maintaining a strong focus on the customer (we defined these, remember) This means approaching data products with a mindset that balances quick wins with long-term scalability and adaptability, ensuring ongoing alignment with business goals.
Any idiot can build a bridge that stands, but it takes an engineer to build a bridge that barely stands.
So when I (and all the other blogs articles and books out there) say, treat your data-as-a-product. What do we even mean? We mean for you to:
Have a User-Centric Focus: Data products should be designed with the end user in mind (these are the customers from our data product canvas). This means, don’t develop a data product in a silo. Develop it with them, not for them.
Be Output-Driven: Data as a product is about continuously ensuring the data adds measurable value to the organization and is aligned to business (This could be an OKR, KPI, or business strategy etc.)
Governed: Like any product, a data product must meet certain standards of quality and reliability. This means focusing on data accuracy, consistency, privacy, and security. (This is where data quality, observability and testing comes in)
Adopt a Reputable Lifecycle: Data products are managed with a lifecycle, from discovery to development, delivery, and continuous iteration. They aren’t one-off projects. (I hope you knew that already after reading this substack)
Adopt Ownership & Accountability: There needs to be clear ownership over data products.
Advocate Discoverable, Scalable, Adaptable & Reusability: Data products should be built with scalability and reuse in mind. As organizational data needs grow, the data product should be able to handle more users or new use cases without needing a complete overhaul. (Bill Schmarzo book covers this quite book)
Writing the Code
A data product itself is made up of multiple components and characteristics to deliver its promise: Building off the legends, a data product has code, infrastructure, data, and metadata and applying a product-mindset to all components is required. Code is written within all components of a data product but will differ depending on your data product strategy.

Some examples:
Data Pipelines: Develop data pipelines that are both reusable and can scale. Develop internal tooling and packages which can be used across teams. Consider the user experience of other data engineers on how future pipelines can be developed easier & ensure they are well documented to improve engineering efficiency.
Transformation: Develop data models that are not tied to a single use case. Prioritize reusability and composability to ensure the models can serve multiple scenarios and be easily integrated into different data products.
Metadata (Schemas, Documentation): How can you ensure engineers, analysts and your future self understand your data product easier? e.g. adopt clear naming conventions, consistent formatting, and self-explanatory schemas2. Have clear documentation on what the model is and what business question it answers.
Remember, adopting a data product mindset whilst writing code means always thinking about the above. You are not just writing code, you’re creating a product that will live, grow, and provide value long after initial development (hopefully).
Note: I only gave some high-level examples here and this is nothing new. There have been many books written on the topic.
Collaboration in the Solution Space
The develop phase is not a solo activity. Regular feedback loops between data engineers, product owners, and domain experts will ensure that development remains aligned with business needs. Utilise collaboration tools such as Git for version control and (DevOps, Jira etc.) Miro for visual collaboration to maintain alignment across teams for less technical folk.
Collaboration is so important and almost the hardest:
Collaboration creates conversations, which creates alignment across teams.
Collaboration forces you to ask questions to other teams, which creates data product reusability.
Collaboration puts engineers in situations to understand the business more, which allows them to document data products better and influences understandability and discoverability.
Iteration & Refinement
Iteration doesn’t stop after the discovery phase. Use early-stage feedback to continuously refine your:
Assumptions, Ideas & Requirements: You’ll learn a lot when you iterate and assumptions you’ve made will change. Iterate and refine.
Solution: The solution can and will change, be open to change and don’t be fall into the trap of Sunk Cost Fallacy.
Its fine to change the solution, and pivot to something else. This is what iteration is all about.
Your data product will evolve as you have real user interactions with your customers and start to measure and validate.
Validating The Data Product Before Deployment
As I mentioned at the start of this post, there is iteration within development, and an important part of that iteration is validation and a constant feedback loop. A popular concept I’ll suggest following is build-measure-learn. As you develop your data product, you need to continuously validate, measure and learn from the interactions with your customers.
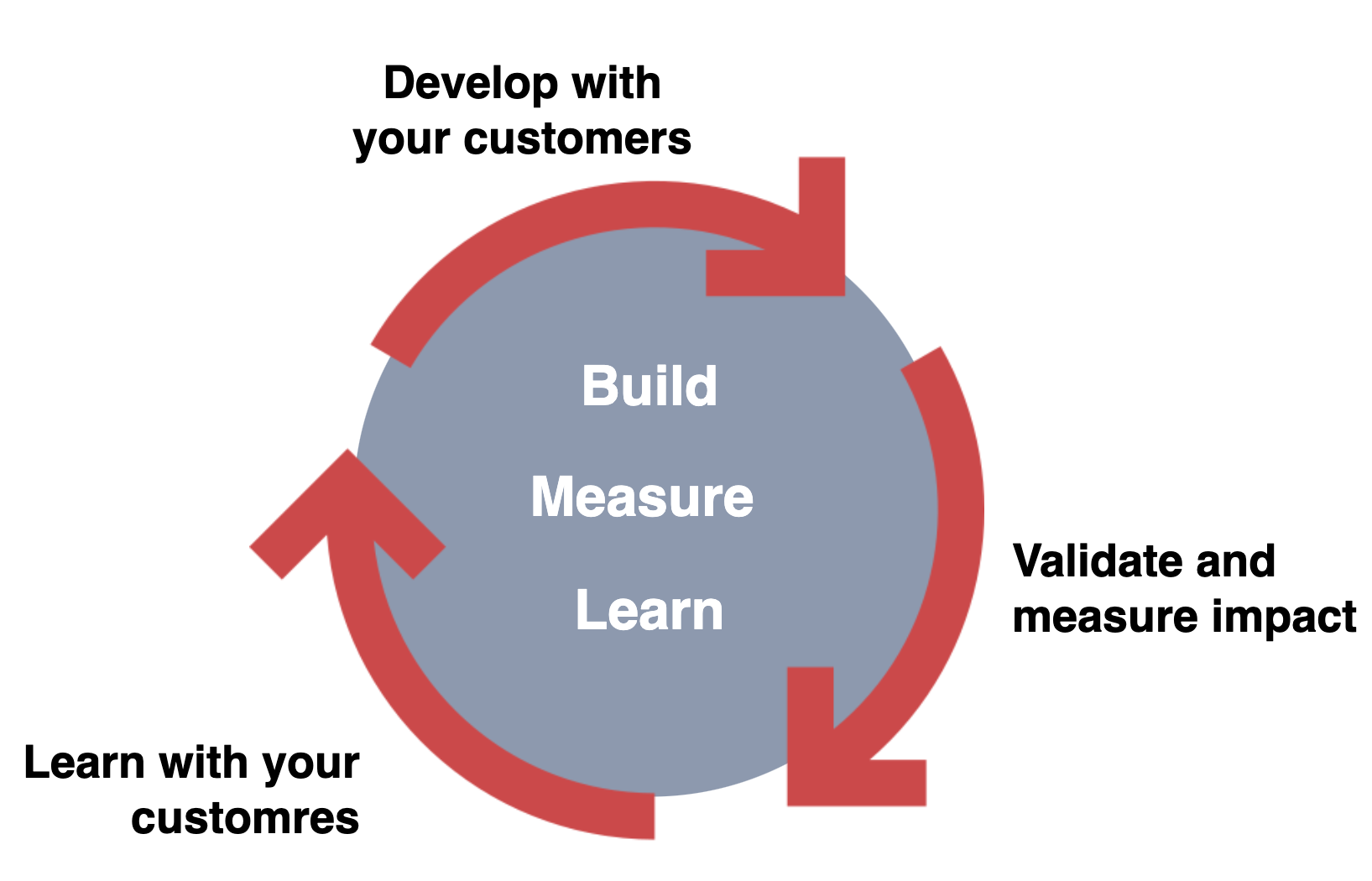
Not only do you learn from customers, they learn from you too, so naturally everything will evolve, and that’s precisely what we want.
The Final Solution
By the end of this phase you should have an agreed solution after many iterations and feedback cycles which your customers were involved in (Built it with them, not for them). The solution should:
Address the problems and outcomes identified in the original canvas from part 1.
Be complete and meet your team’s definition of done. The final solution is no longer a proof of concept and should be ready for production.
Be documented to increase discoverability and reusability.
In the next phase I’ll introduce you to the data product based on the first post and get our data product ready for deployment in production and ensure monitoring, observability, tests are in place to ensure trust is developed and sustained. The outcome of this will be value that can be realised to its intended customers, continuously.
Thanks for reading! If you enjoyed this post, please consider subscribing.
🍔 GrillTech Burgers, a gourmet hamburger chain, relies heavily on their Azure Data Platform to manage operations and customer engagement. However, escalating platform costs are impacting profitability, and their Chief Data Officer has urgently requested a solution.
I am not saying copy this but just have a look at what a standard could look like https://docs.oracle.com/cd/B19306_01/server.102/b14200/sql_elements008.htm and how you could automate this to ensure consistency.