



Reusability in the Context of Data Models with DBT
Creating reusable data models & data products. What does that even mean!!

So what is reusability? When you read practitioners say “Ensure a data product is reusable?”, What does that practically mean?

A data product is reusable in that data consumers, including other systems, can use it in different ways within the scope of its functionality.
- Starburst
A data product is a reusable data asset built for a specific purpose. However, it is generally less reusable since it is tailored to particular use cases.
-Airbyte
Reusability in the context of data modeling is a crucial step to enable data to be used across multiple use cases and data domains. Reusability is a design decision and if not done correctly data models will be developed for single-use cases and you will not reach economies of scale 1
I believe reusability in data modeling can be implemented in two ways:
Enhancing the user experience to encourage reuse (e.g., discoverability, understandability).
The design of the data model to facilitate and support reuse (e.g., data architecture).
We’ll be covering the latter in this post and how it can be applied to data modeling using our DuckDB Chinoon project. Before diving into the principles and practical implementations I’ll quickly cover why you’d want to consider reusability in your data product lifecycle.
Why invest in reusability?
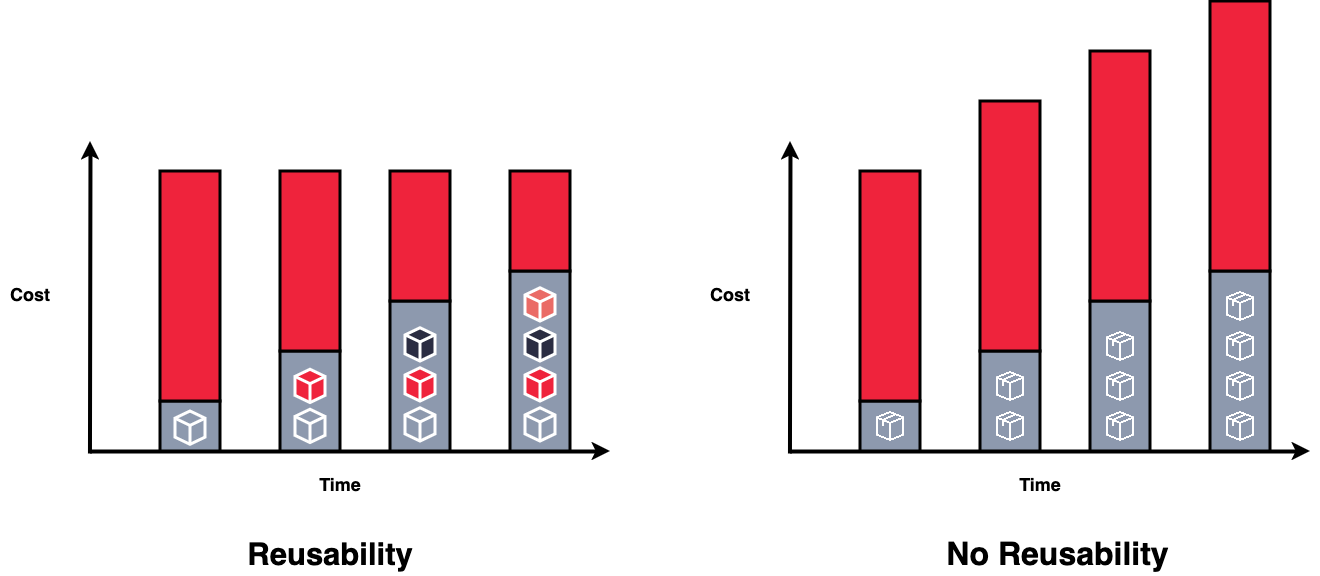
Consider the below diagram for an organisation adopting reusability vs not.
What does this mean in a nutshell? The more data product you develop? the lower the average cost of each data product over time.
Some other key benefits of adopting reusability are:
Cost: increases the return on investment by reducing the development cost for each new data product.
Speed to insight is greatly increased as data consumers can access data models faster.
The maintainability of your data platform will increase due to a well-designed data architecture (Reduced duplication, increased consistency)
Data models can be used for multiple use cases (This is the big one!!!)
Bill Schmarzo put it nicely. “an asset that never depletes, never wears out, and can be used across an unlimited number of use cases at near-zero marginal cost”2
Developing data models for reusability
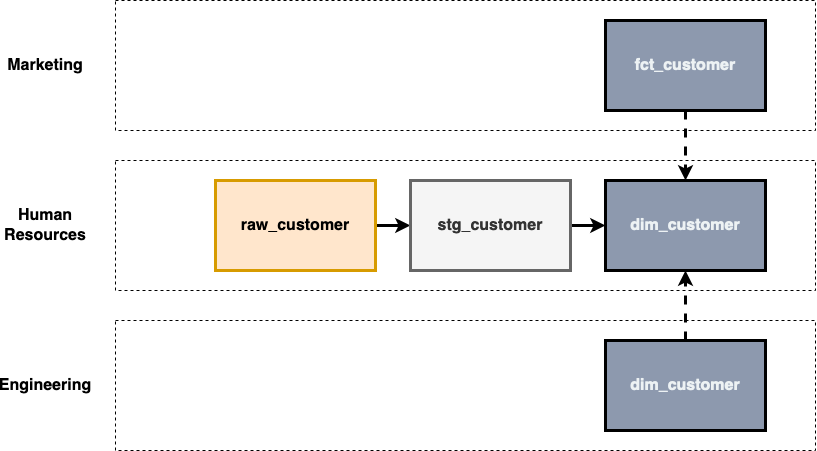
Suppose a company has three domains, marketing, human resources (HR), and engineering. It’s chaos, marketing ingests its own customer data and builds its own facts/dimension, HR is on a DBT journey and is following best practices and engineering doesn’t like the fact table HR created so they built their own dimensions and now have conflicting metric definitions. Its the genisis of a house of cards!
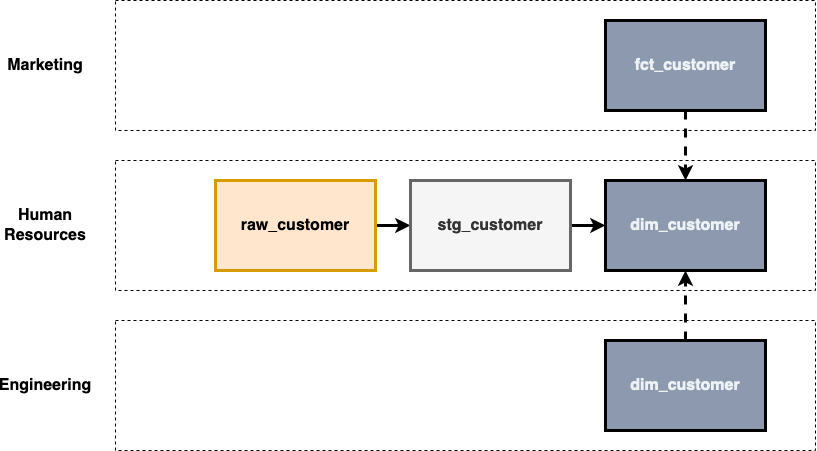
How could we implement this better?
Can we borrow some concepts from DDD to help architect the data models across multiple domains? In the world of DDD, they have a concept called a Shared Kernel.
A Shared Kernel is a concept where a subset of a domain model is shared between different bounded contexts. This shared subset is typically a set of entities, value objects, or other model elements that are common to both contexts and need to be consistent across them.
So how can we apply this concept to data modelling and apply some best practices to allow reusability?
Identify common attributes used across all domains and implement them in the base model.
Attributes and logic related to specific domains should reside in that domain data model whilst remaining consistent across all domains.
Duplicating code should be avoided; ensure that shared logic across domains sits within the base model and encourages collaborative contributions. e.g. marketing will likely have a LTV attribute that will only reside in their domain.
Name and document your models to give other data consumers and engineers a better user experience and increase your chance of reusability.
Building on the previous point, consider a consistent column naming standard. The following post introduces a concept called Column Names as Contracts.
Don’t filter dimensions/facts which would block future use cases.
In Kimball, this design pattern of breaking dimensions into smaller dimensions is known as snowflaking.
How could this be practically implemented in DBT?
You can check out a practical implementation of how the above was implemented with my DBT DuckDB repo. The implementation is straightforward. Each domain has its own schema and marketing and engineering build off the dim_customer in the HR domain. Any changes to logic, new columns, etc are available to other domains and they are empowered to add/remove the columns they need. I would suggest using model contracts to reduce the possibility of breaking changes between domains.

Closing out
No data architecture will create reusability without strong communications between teams and a clear incentive for data model reuse. This post was more a thought experiment than a silver bullet to model reusability.
This approach isn’t for all organisations, if your organisation has adopted a OBT3 to put all customer data in one table you may think this is a bit back to front.
I'd love to hear from others about their experiences with adopting data model reuse across various domains in larger organisations. What strategies and incentives have you implemented to encourage your teams to embrace this practice?
Until next time!
-Ash
Economies of scale refer to the cost advantages that a business obtains due to the expansion of its production, where the cost per unit of output decreases as the scale of operation increases. In the context of this post the cost advantage is not need to start every data project from scratch.
https://www.amazon.com.au/Economics-Data-Analytics-Digital-Transformation/dp/1800561415
https://dataengineering.wiki/Concepts/One+Big+Table