

Data Product Lifecycle for continuous & repeatable value
From Discovery to Delivery: Your Step-by-Step Guide to Building Effective Data Products

I’ve written a series of posts which will take you through a lifecycle to develop Data Products with a strong focus on product thinking and value creation. The lifecycle is an adaption building off a lot of the already great content that is available online but targets more at readers that are not on a data mesh journey.
What am I going to cover?
Discovery & Definition: Steps to Shape Successful Data Products - Part 1 [Available]
Explore the essential steps for framing data problems, validating hypotheses, and defining value. Learn to use a Data Product Canvas and develop a Data Product Specification with your stakeholders (and not on your own).From Canvas to Code - Part 2 [Available]
Dive into the core principles of Data Product development, including discoverability, accessibility, and interoperability. Get practical code examples and guidance on creating reusable, trusted data products.Delivering and Iterating on Your Data Product Promise - Part 3 [Available]
Learn to assess if your data product meets its goals, gather feedback, and iterate for continuous improvement. Discover practical strategies for evolving your data product with the business.
Data Product Lifecycle
Building on the shoulders of others in the industry, the data product lifecycle is an adaptation of the double and triple diamond technique and pulls a lot of inspiration from some existing great articles. Where I have tried to differentiate is by providing more practical and applicable advice with code and tooling. All of the graphics and code is open-source.
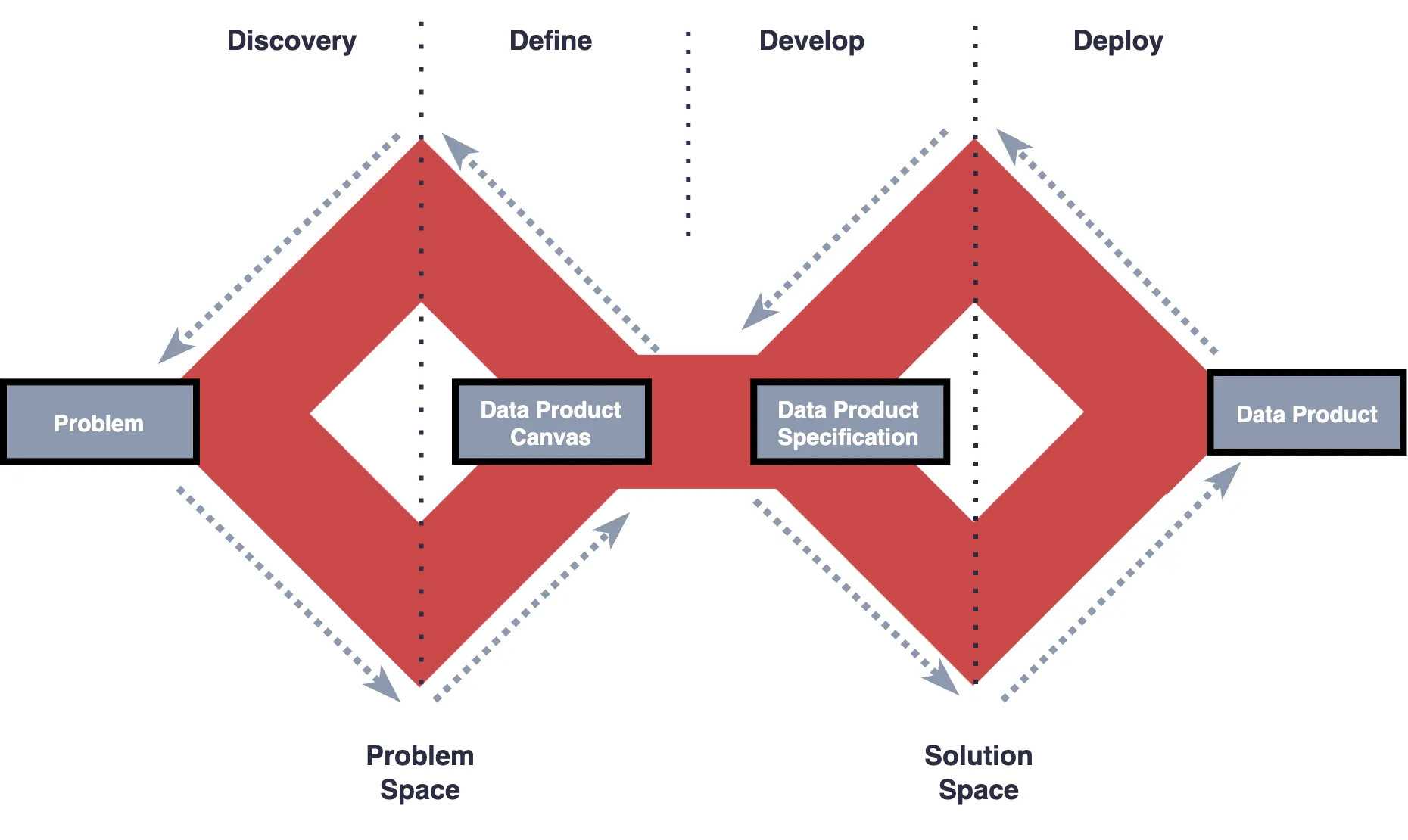
Using this fictional example; how might you go through this lifecycle?
You work for a company called TeraDynamics and your cloud spend is out of control and you have no idea why. Your CTO has asked you to get on top of it but gave no direction on how. Teams across the company are accountable for their cloud spend but they don’t even know how much they spend or the value that spend is delivering.
Discovery:
You start by investigating the uncontrolled cloud spend, interviewing teams to understand their usage, and analysing billing data. The goal is to uncover the root causes, like lack of cost visibility and resource inefficiencies. Where are costs coming from? What departments etc.
Define:
With the insights gathered, the problem is reframed: "How might we give teams clear visibility into their cloud spend and ensure it aligns with the value delivered?" Is the problem that they didn’t even know the cost existed? The problem statement should be clearly defined and agreed upon within the team.
Develop:
Solutions are brainstormed and prototyped, such as creating dashboards for cost visibility and tools for budgeting. These MVPs are tested with teams for feedback and captured in your backlog.
Deploy:
The final solutions are implemented across the company, with training provided and ongoing monitoring established. The impact is measured to ensure better control over cloud spend and value clarity.
I hope you enjoy the series as much as I’ve enjoyed researching and writing it. Be sure to subscribe below so you get notified when I release each part.
Thanks for reading.
Subscribe below to get notified when I release part 1 next week.