



Data Product Testing - A Primer
How to approach data testing and avoid creating that Slack channel of data incident alerts everyone mutes or ignores.

Building data products is easy, but building sustainable data products that will continuously deliver value is a different story. One part (albeit a big part) of developing a sustainable data product is ensuring the input of your data product (the data) is continuously of the expected data quality. In this article, our data product is a data model and we’ve built one in DBT with DuckDB using the chinook dataset.
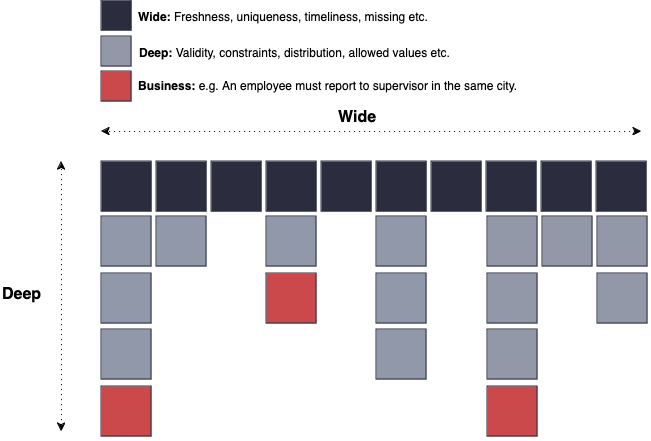
Throughout this post, I’ll reference the diagram below, which I first discovered through Bigeye. We’ll delve into its details, but for now, understand that it represents a hierarchy of needs. At the base are foundational technical tests, while at the top are domain-specific business tests.

Testing your Data Product
If you are thinking about testing your data (and you should be) I'll assume you've spent a bit of time with your data getting to know it, you know where it comes from, you know how it’s created in the source system, you know the schema and possibly across some of the business logic behind the data. With this knowledge you can develop some foundational tests to increase the reliability of your data; For example, this could be implemented using DBT Tests.
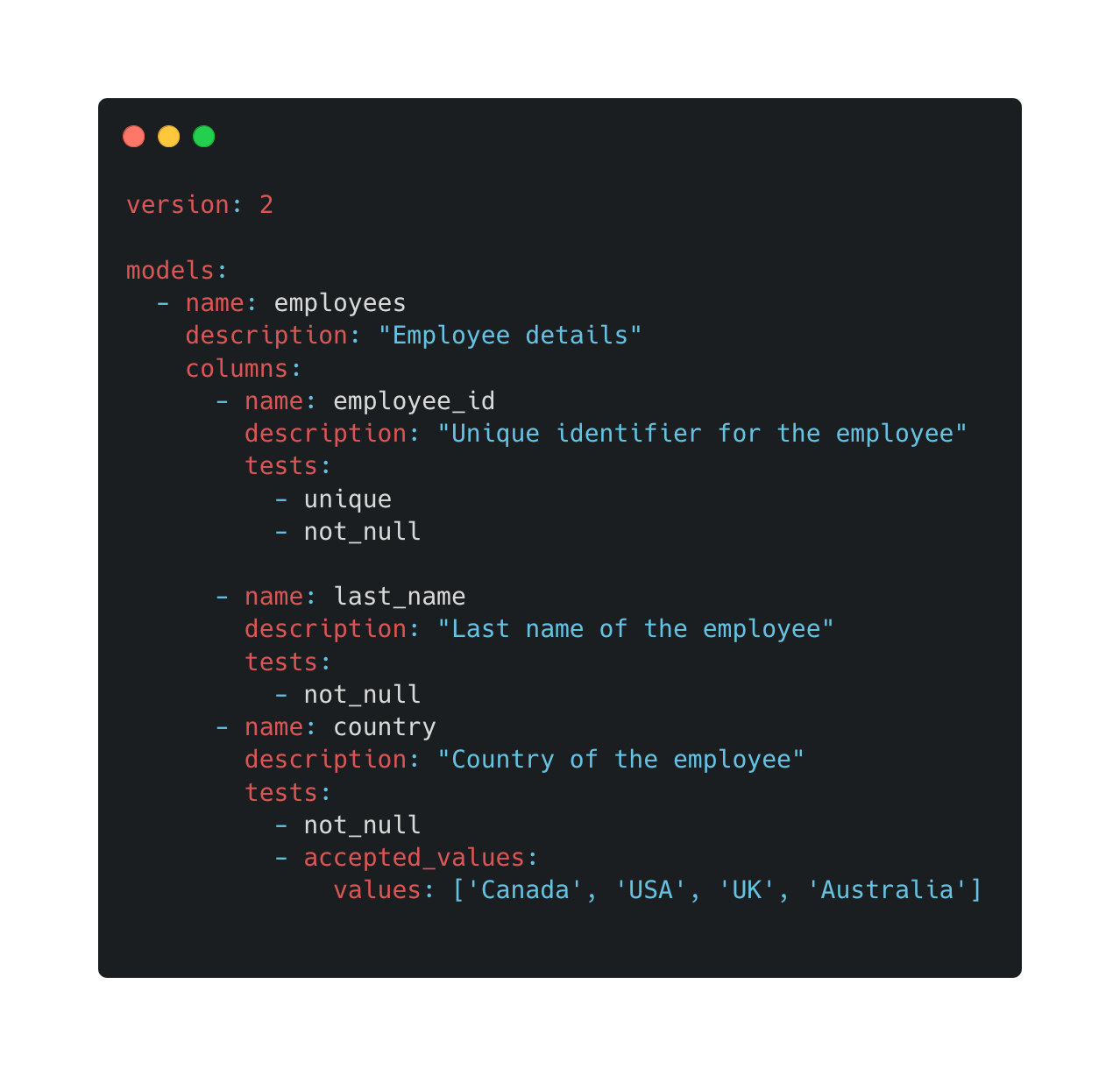
The above is a pretty basic test, it validates primary keys for uniqueness, ensuring null values, and for the column country, we are testing for allowed values (because we knew some data realities remember). What if we wanted to go deeper into testing and understand its current quality, highlight missing values, inconsistencies, or relationships to other columns? Data profiling is a great technique to deliver this.
Expanding on your foundational tests with Data Profiling
Profiling data before writing tests is extremely valuable as it'll give you an in-depth understanding of the characteristics and nuances of your data. For example, it will help you understand the freshness, completeness, missing values, known values (distributions), how complete your data is, and what constraints your data has.
For profiling our dataset we’ll use YData, but there are many other open-source alternatives 1. I don’t intend to explain what data profiling is, and how to do it I merely want to demonstrate how the process can be used to influence your data tests.
Based on the data profiling results, define test cases that align with the expectations and rules identified from the profiling analysis. Remember, go wide, then deep.
Below are some principles to consider when reviewing the profiling output and determining the necessary tests.
Principles to consider when writing tests
Focus on foundational tests first
Test everything on the bottom layer first, (freshness, no duplicates, uniqueness etc). The alerts tab in the data profile can help identify this if you are unsure where to start. I would consider it best practice to have foundational tests on all tables in your data product.

Go deep in your tests only after you are confident with foundational tests.
If your tests are passing and your data model needs additional confidence you can go deeper and start to apply tests on validity, distribution, or acceptable ranges (no dates in the past, etc). If these tests are not important to assert and raise exceptions when it fails then it’s a good indication you do not need a test. It’s a common fallacy that engineers either do no or too many tests.
Testing your data against the real world!
Lastly, to build that final level of confidence and additional trust in your data product you can start to build out tests on the rules and realities your data must comply to. These rules are typically driven by business processes or requirements in a project. e.g., A row must exist for an artist where an album exists (code). Don’t get too caught up writing tests for every piece of business logic you have (you will regret it!).
Focus on the basics before investing in end-to-end observability platforms
There are some amazing data observability platforms available on the market, but if you are just starting on your data journey then there are other areas you should invest your time and money in first.
Incident management on data quality failures
When a data quality test fails a log should be created for your records2 but an alert should be optional. Not all failures warrant an alert to be sent to Slack unless you intend for someone to take action on it. Unless you are confident you’ll respond to the alerts I encourage you to monitor for a period and then establish alerts. Lastly, when you do define alerts ensure you have established owners for all data, as these data owners need to be accountable for the resolution.

Takeaways
Data profiling: Often a missed step before writing data tests. Data profiling can speed up your test development and give you ongoing confidence in your data profile. Don't become a data pipeline babysitter.
Go wide, then deep: Don't test everything. Only test what matters. This isn't easy to define & will often require you to get close to customers making decisions on your data product as they’ll know the impact when data is wrong (this is what matters).
Lastly, Speak to your subject matter experts. There is only so much you can learn from manually exploring and profiling a dataset. Get as close to where the decisions are made and validate your assumptions.
Until next time!
There are many open-source data quality solutions to assist you in managing and profiling your data.
If you are using DBT you can persist your logs in your data platform for monitoring and historical purposes. Most end-to-end observablity platforms also integrate DBT tests so you have a single plane of glass for data testing.