

Building Trust into your Data Product
Nobody Uses Untrustworthy Data (But Everybody Blames the Data Engineer)

I hope you enjoy this read! I can’t remember the exact moment I decided to dive into the 'black hole' of trust, what it means and how data engineers can build it. But it’s an area that deserves more attention in our field. Enjoy!

Almost every article you read about data products defines a strong characteristic to be “trustworthy”. So what is trust, and how can engineers in data teams change their mental models to develop trustworthy data?
Key takeaways:
1️⃣ Trust Is Essential: Without trust, data products won’t be used for decision-making.
2️⃣ Data Engineers Build Trust: Through practices like documentation, testing, and transparency, data engineers lay the foundation of trust.
3️⃣ Trust Takes Time: Building trust is gradual but fragile, earning it takes consistency.
Trust is like a glass, once it's broken, it can never be repaired. You can attempt to repair it, but the idea that trust, once damaged or lost, is difficult to restore fully.

Before we dive into the details; let’s break down the word trust and how it relates to data.
So what does it mean if someone doesn’t trust your data product or data?
It’s highly likely they won’t use it to make decisions.
If they don’t trust some data, they likely don’t trust any of your data.
Something triggered this distrust (broken report, duplicate data in a table).
Trust is the willingness that someone will use your data, or not. Trust can be conveyed both implicitly, and explicitly (more on this later). Trust is a huge part of developing data products, and data engineers play a considerable part in building and continuously sustaining trust.
Let’s lay down some facts on the word trust and what it means.
Trust is earned.
Trust is earned gradually.
Trust is subjective
Trust takes a long to earn, but can be lost instantly.
So how do you, as a data engineer, influence trust and adapt your mental model.

Trust Mental Model
I find frameworks and blueprints great tools to develop and train mental models when approaching a problem and for a team to have a shared understanding of the approach.
The blueprint I have adapted, and we are going to use for applying trust to data products, is Mayer's Trust Model1. The Mayer's Trust Model model is ideal because it’s simple and iterative, which aligns well with the Data Product Lifecycle approach.
Team members can evaluate trust-related challenges through the same lens & easier to discuss trust-related issues with other engineers in the team.
For example, assume you have a critical data product and its adoption, trust and usage is trending down. Having a model that you can refer to can help.
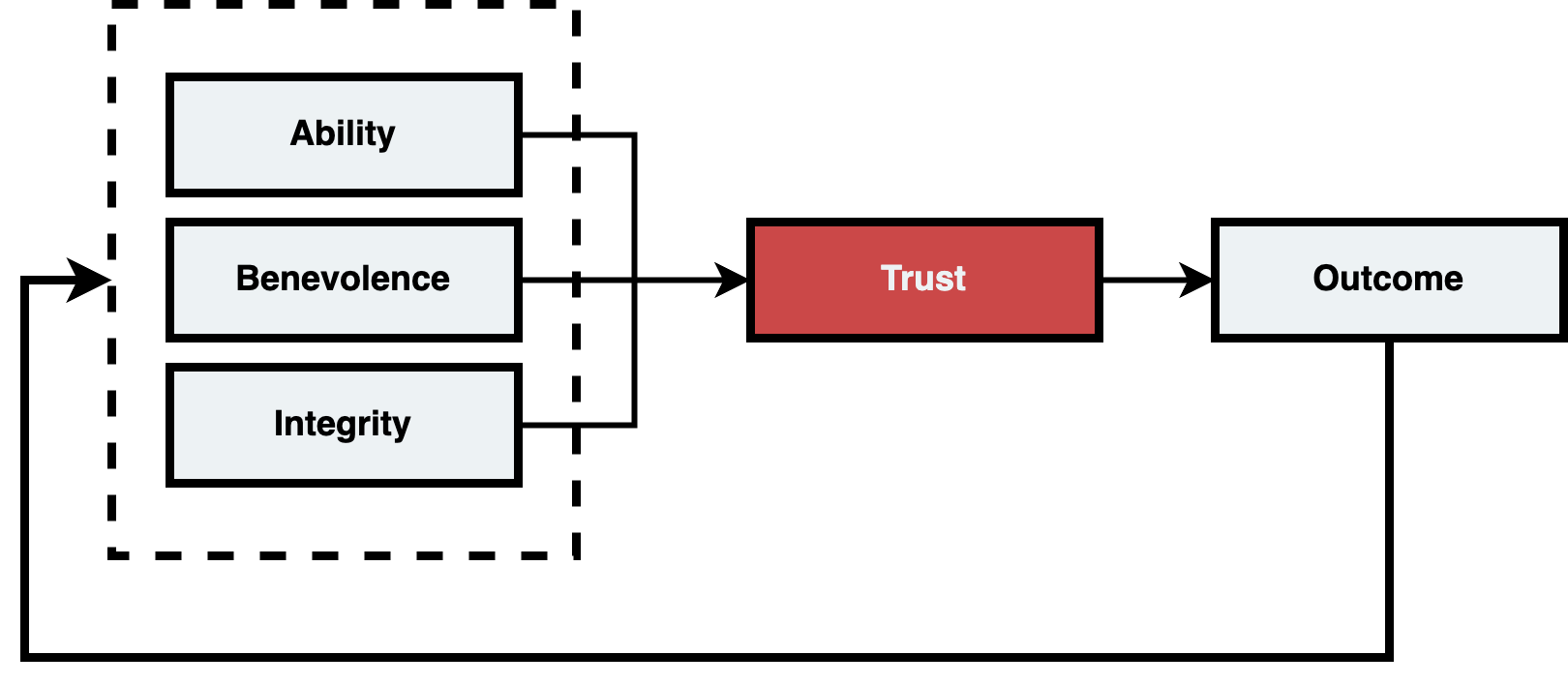
Ability (Technical Trustworthiness)
Demonstrating technical competence and reliability in delivering data.
Practical examples:
Robust coverage in logging: I love logs, don’t you? Logging is critical for developing trust, as the logs are required to not only let customers know when things have failed, but to let them know when things are good.
Scalable, resilient and ability to handle edge cases: Anyone can build a pipeline or a data model that works. It takes a good engineer to develop a pipeline that can stand the test of time, can scale and evolve.
Test Coverage: It doesn’t matter what you’re building. There is always a way you can implement tests.
Benevolence (Good Intent)
Showing genuine care for data consumers' success
Practical examples:
Documentation: The purpose of documentation is to accelerate understanding for other engineers and your future self. This is particularly important for data models and customer-facing data products where initial understanding is required (Clear metric definition, data model purpose etc.)
Metadata: Just like documentation, metadata can accelerate understanding and time to insight. Some examples within the realm of data engineers are establishing data ownership, column definition, business definitions, SLOs.
Supportability: Don’t build things and abandon them. Ensure you offer channels and processes for customers to get help to ask questions (Slack, Teams, Email etc.) If they can’t get help, you won’t sustain trust.
Communication: Whilst product owners are the typical conduits to the business, there isn’t a valid reason why engineering can’t get closer to the business and often communicate, ask for feedback, setup 1:1 to understand what’s working and what isn’t.
Integrity (Principles)
Maintaining consistency and transparency
Practical examples:
Clear data lineage: Where is your data sourced from? Is their entire lifecycle supported and clear?
Transparent processes: It’s open and known to your customers on how the data product will change and evolve. Breaking changes just don’t happen, but proactive communication is done (refer to intent, you need to genuinely care for data consumers' success.)
Consistent: Be consistent in everything! Would you trust your car if the fuel gauge light came on occasionally? Would you enter a traffic intersection if green meant something different every interaction? Consistently document, follow your process, notify customers of failures and success.
The above isn’t exhaustive, it’s to highlight that data engineers, like data stewards, governance managers all play a role in building and sustaining trust to data and data products. So the next time you are having issue consider stress testing your concerns with the model.
Is it an Ability problem? (Perhaps there are reliability/ scalability issues we can improve on)
Is it a Benevolence concern? (Are we meeting our users' needs?, perhaps the business changed and we need to change our assumptions)
Is it an Integrity gap? (Have we been consistent enough in our SLA & SLOs?2)
What are some signals of trust?
Data Certification
Consider defining a technical and business rule which can easily let customers know it can be trusted. Think of it as a data trust seal or endorsement. Lots of data catalogs offer this type of functionality, but what I don’t like is that users can click it manually. It must be automated and consistently, and you should be able to lose the trust seal.
Usage & Adoption Metrics
Let others know how often a particular data product is used in the business and how. Do you trust a GitHub repo more if it has more stars? I do. Some more example below.

Documentation
Documentation gives end users the confidence that your data product is well-maintained, and created with user understanding in mind. Would you ever use a GitHub repo with no readme.md? If you see a well-crafted readme with passing builds, does it give a strong signal of trust to you?
Closing comments
Trust begins with value, prioritise the customer’s value above your data stack.
Trust in data products multiplies with each positive experience and valuable interaction, but when lost, it compounds its descent like a snowball rolling down a hill!
Be honest! If it’s broken, tell your customers.
The more trusted a data product is, the more it’s likely to be used and shared with others.
Building trust takes effort.
Thanks for reading. I’m glad you stuck around!
Subscribe to Ash Substack and follow him on LinkedIn
https://www.jstor.org/stable/258792
SLO (Service Level Objective): Internal targets that define data reliability, such as freshness ("updated every 6 hours") or quality ("98% valid records"). SLA (Service Level Agreement): Formal contract guaranteeing specific service levels to customers, with defined consequences if breached.